Tout savoir sur le comparateur
Le comparateur permet de créer des jeux de données de préférence centrés sur des usages réels exprimés dans les langues européennes.
Accéder au comparateur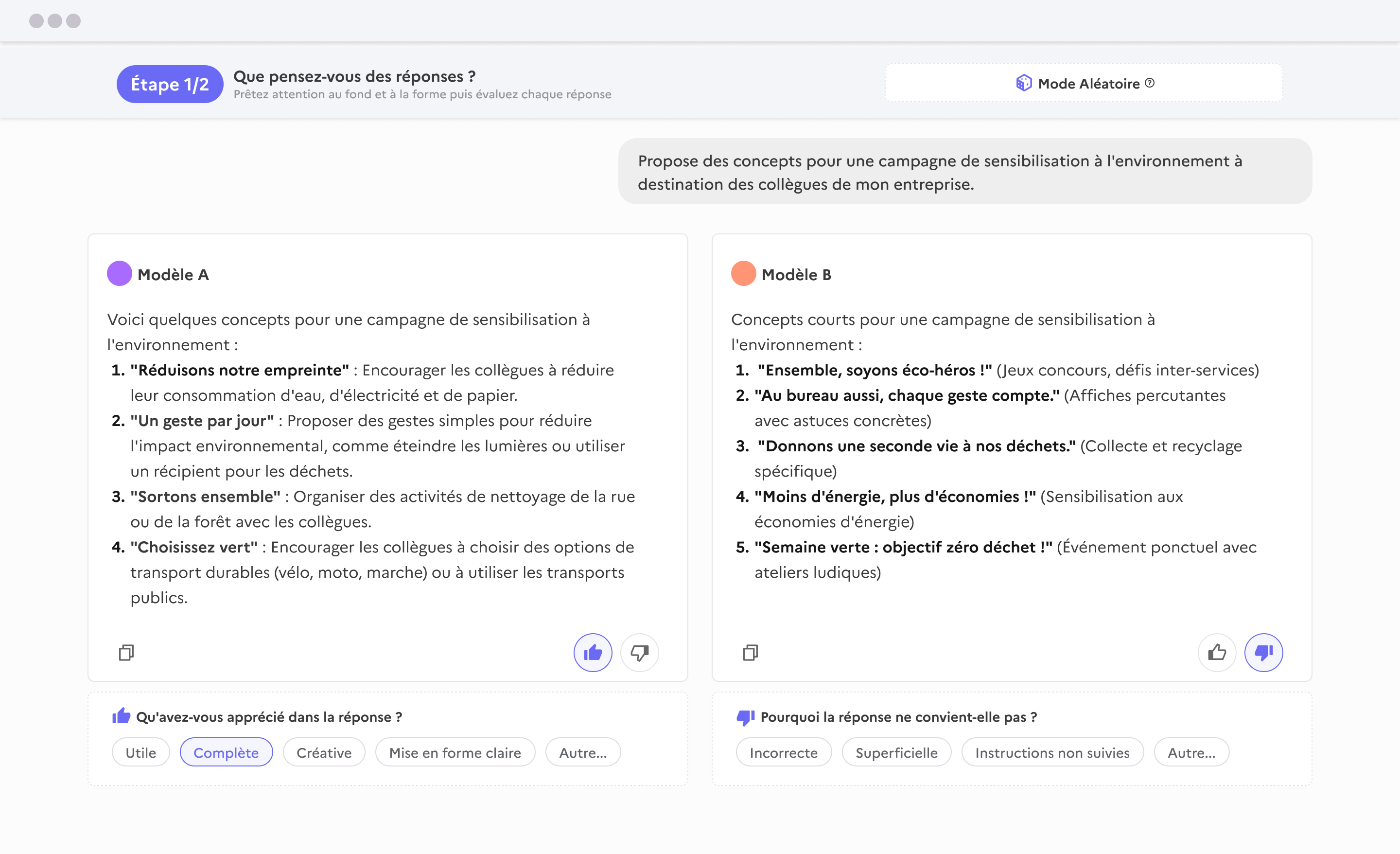
L’application développée répond à plusieurs enjeux
Biais culturels et linguistiques
Impact environnemental
Pluralisme des modèles
Esprit critique et questions sociétales
Le comparateur devient européen !
A partir de l’automne, la Lituanie, la Suède et le Danemark rejoignent l’aventure ! Le comparateur sera mis à disposition de leurs citoyens dans leurs langues nationales. L’objectif est de créer des jeux de données de préférence afin d’améliorer les futurs modèles d’IA dans ces langues européennes.
Vous souhaitez disposer du comparateur dans votre langue ?
Nous contacterLes modèles d’IA conversationnelles respectent-ils la diversité des langues européennes ?
Réponses stéréotypées
Les systèmes d’IA conversationnelle donnent l’impression de parler toutes les langues mais les résultats qu’ils génèrent sont parfois stéréotypés ou discriminants.
Données d’entrainement majoritairement en anglais
Les IA conversationnelles reposent sur des grands modèles de langage (LLM) entraînés principalement sur des données en anglais, ce qui crée des biais linguistiques et culturels dans les résultats qu'ils produisent.
Diversités culturelles et linguistiques négligées
Ces biais peuvent aussi se traduire par des réponses partielles voire incorrectes négligeant la diversité des langues et des cultures, notamment européennes.
Comment réduire les biais culturels et linguistiques de ces modèles ?
L'alignement : une technique de réduction des biais qui repose sur la collecte des préférences d’utilisateurs
L’alignement, étape décisive d’instruction du modèle
L'alignement intervient après l'étape de pré-entraînement d'un modèle de langage, comme une étape de « finition » ou de « polissage ». Lors de son pré-entrainement, le modèle apprend à prédire le mot suivant et devient capable de générer du texte cohérent.
L’étape d’alignement consiste à apprendre au modèle à mieux répondre aux besoins humains, c’est à dire à le rendre plus pertinent (le modèle répond « mieux » aux questions), honnête (capacité à assumer « qu’il ne sait pas répondre » quand il n’y a pas suffisamment de données), et inoffensif (éviter de générer des contenus dangereux ou inappropriés).
Sans alignement, un LLM pourrait être techniquement compétent mais difficile à utiliser en pratique, car il ne comprendrait pas vraiment ce qu'on attend de lui dans une conversation.
Des jeux de données spécifiques
L'alignement utilise des données très spécifiques, spécialement créées pour enseigner au modèle comment « bien » se comporter.
Les données de préférence constituent un type particulier de données d’alignement, aux côtés des données de démonstration (exemples de conversations entre humains et assistants IA, rédigées par des annotateurs experts selon des consignes précises de ton et de style), des données de sécurité (exemples spécifiques enseignant au modèle à éviter les contenus dangereux en montrant comment refuser les demandes problématiques) ou des données spécialisées couvrant des domaines spécifiques (médecine, droit, éducation…).
Les données de préférence présentent plusieurs réponses possibles à une même question, classées par ordre de qualité par des évaluateurs humains : les utilisateurs indiquent quelle réponse est la meilleure selon des critères donnés, telles que la pertinence, l’utilité, la nocivité. Une fois constitués, ces jeux de données sont utilisés pour entraîner les modèles en les ajustant selon les préférences exprimées par les utilisateurs.
Peu de données de préférence en langues européennes
Les données de préférence sont couteuses à produire car elles nécessitent du travail humain qualifié pour chaque exemple. Des plateformes telles que https://chat.lmsys.org/ permettent de constituer ces jeux de données de préférence mais peu d’utilisateurs s’en servent dans leur langue d’origine.
Les jeux de données de préférence sont rares, voire inexistants dans les langues européennes. La part des questions posées en français dans le jeu de données de LMSYS est par exemple inférieure à 1%.
comparIA est un exemple de dispositif permettant de collecter des conversations dans de multiples langues, incluant des références culturelles spécifiques à chaque région ou pays : tâches courantes, traditions culinaires locales, systèmes éducatifs, références historiques ou littéraires, etc.
Diversifier les données pour réduire les biais
Pour refléter la diversité des cultures et des langues dans les résultats générés par les modèles, les jeux de données d’alignement doivent inclure une variété de langues, de contextes et d’exemples issus de tâches courantes des utilisateurs. La diversification des données d'alignement permet d’améliorer à terme les performances d’un modèle à double titre :
D'une part, elle réduit les biais culturels en évitant qu'une seule perspective - souvent anglo-saxonne - domine les réponses de l'IA. Le modèle apprend ainsi à reconnaître qu'il existe plusieurs façons valides d'aborder une même question selon le contexte culturel.
D'autre part, cette exposition à la diversité de langues et de cultures favorise l’adaptation des réponses à des contextes spécifiques : un utilisateur français recevra des conseils adaptés au système français, tandis qu'un utilisateur danois obtiendra des informations correspondant à son contexte national.
Le résultat est un modèle d’IA conversationnelle plus inclusif, capable de tenir compte des différentes cultures.
Les partenaires
France

")







Danemark


L’équipe compar:IA - France

Lucie Termignon
Fondatrice - cheffe de produit
Janvier 2024 - Décembre 2025

Simonas Zilinskas
Chef de produit - ex chargé de déploiement
Depuis Décembre 2024

Aurélien Barot
Designer produit UX/UI
Depuis Juin 2024

Nicolas Chesnais
Développeur Full stack
Depuis Juin 2025

Hadrien Pelissier
Développeur Full stack
Juin 2024 - Novembre 2025

Elie Gavoty
Développeur Full stack
Depuis Novembre 2025

Mathilde Bras
Responsable de l'Atelier numérique / Product Ops
Depuis Septembre 2024
compar:IA en quelques dates
Novembre 2025
Objectif des 200 000 votes atteint !
Avec plus de 500 000 conversations uniques depuis le lancement de compar:IA.
compar:IA reconnu comme Bien Commun numérique
Le service est reconnu comme un bien public numérique par l’Alliance Digital Public Goods.
Ouverture de compar:IA en danois
Le Danemark rejoint l’aventure en proposant le comparateur dans sa langue national avec un nom de domaine dédié.
Publication du classement compar:IA
Construit en partenariat avec le Pôle d'Expertise de la Régulation Numérique (PEReN), le classement compar:IA repose sur l’ensemble des votes et réactions collectés depuis l’ouverture du service au public en octobre 2024.
Septembre 2025
Lancement des « Duels de l’IA »
Création de ce nouveau format d’atelier ouvert à tout public, pour découvrir les coulisses des IA génératives et réfléchir à leur impact environnemental, et publication du kit de facilitation associé à l’extension « Duels de l’IA ».
Été 2025
Extension à l’échelle européenne
Partenariat avec le Danemark, la Suède et la Lituanie pour ouvrir le service dans leur langue.
Juin 2025
Publication des trois jeux de données compar:IA
Mise à disposition de ces trois jeux de données, conversations, réactions, votes, sur HuggingFace et Data.gouv.fr.
Mai 2025
Objectif des 100 000 votes atteint !
Et première réutilisation du jeu de données avec Bunka.ai qui a mené une étude approfondie sur les interactions entre les utilisateurs de la plateforme.
Mars 2025
50 000 votes sur le comparateur !
Création et mise à disposition du premier jeu de données compar:IA en français regroupant les questions et préférences des utilisateurs de la plateforme.
Février 2025
Journée comparIA à la BnF pendant le sommet pour l’action sur l’IA
Plus de 300 personnes dans le cadre de conférences et d’ateliers dédiés aux enjeux éthiques, culturels et environnementaux des systèmes d'IA conversationnelle.
Janvier 2025
compar:IA v2
Lancement de la nouvelle fonctionnalité de choix du mode de sélection des modèles.
Octobre 2024
Lancement officiel lors du Sommet de la francophonie à Villers Cotterêts !
Présentation officielle et premiers déploiements de l’outil.
Juin-Sept 2024
Conception du produit minimum viable
Développement des premières fonctionnalités du comparateur et intégrations des retours des premiers bêta-testeurs.
Janv-Mars 2024
Phase d’investigation
Entretiens avec des acteurs de l’écosystème et premières hypothèses de solution sur la problématique : « Comment faciliter l’accès à des données en français pour l’entrainement des modèles de langue ? ».
Les modèles de langage conversationnels actuels sont incapables de citer les sources qu'ils ont utilisées pour générer une réponse. Ils fonctionnent en prédisant le mot suivant le plus probable en fonction de la distribution statistique des données d'entraînement. Bien qu'ils puissent synthétiser des informations provenant de diverses sources, ils ne conservent pas la trace de l'origine de ces informations.
Cependant, il existe des techniques comme la Génération Augmentée par Récupération (RAG) qui visent à pallier cette limitation. Le RAG permet aux modèles d'accéder à des bases de connaissances externes et de fournir des informations contextualisées en citant les sources. Cette approche est essentielle pour améliorer la transparence et la fiabilité des réponses générées par les modèles.
Vous avez posé la question suivante “explique-moi la motion de censure à l'œuvre actuellement en France à l'Assemblée nationale et cite-moi tes sources” et avez été déçu·e des réponses ? C’est normal…
Les modèles d'IA conversationnels “bruts” ne peuvent pas répondre aux questions sur l'actualité la plus récente. Ils sont entraînés sur des ensembles de données statiques et ne peuvent pas interagir avec le web ou ouvrir des liens. Ils n'ont pas la capacité de se mettre à jour en temps réel avec les événements qui se déroulent dans le monde. Les informations auxquelles le modèle a accès sont limitées à la date de son dernier entraînement.
Par conséquent, si vous posez une question sur un fait d’actualité récent, le modèle s'appuiera sur des informations potentiellement obsolètes, risquant de générer des réponses inexactes.
Dans le cas de Perplexity, Copilot ou ChatGPT, les modèles d’IA conversationnelle dits “bruts” sont associés à d’autres briques technologiques qui permettent de se connecter à internet pour accéder à des informations en temps réel. On parle alors “d’agents conversationnels”.
Si vous intégrez une URL dans une requête, le modèle conversationnel ne peut pas y accéder directement. Les modèles de langage traitent le texte de la requête mais n'ont pas la capacité d'interagir avec le web ou d'ouvrir des liens. Ils sont entraînés sur un ensemble de données textuelles fixes et leurs réponses reposent sur ces données d’entraînement. Lorsqu'une question est posées, les modèles utilisent cet entraînement pour générer une réponse mais ne peuvent pas accéder à de nouvelles informations en ligne.
Par analogie, imaginez un étudiant passant un examen sans accès à internet. Il peut utiliser ses connaissances acquises pour répondre aux questions, mais ne peut pas consulter de sites web pour obtenir des informations supplémentaires.
Il arrive que les modèles perdent le fil d'une conversation en raison de leur fenêtre de contexte limitée. Cette « fenêtre » représente la quantité d'informations précédentes que le modèle peut retenir, agissant comme une mémoire à court terme. Plus la fenêtre est petite, plus le modèle est susceptible d'oublier des éléments clés de la conversation, conduisant à des réponses incohérentes. Les conversations longues ou complexes peuvent rapidement saturer la fenêtre de contexte, augmentant le risque d'incohérence.
Par analogie, imaginez une personne qui ne se souvient que des cinq dernières phrases d'une conversation. Si la conversation est courte, la personne peut suivre. Mais si la conversation devient longue, la personne oubliera des informations cruciales, ce qui rendra ses réponses incohérentes. De même, un modèle d'IA avec une petite fenêtre de contexte peut « perdre le fil » d'une conversation lorsque trop d'informations sont échangées, oubliant des éléments clés et produisant des réponses qui n'ont plus de sens.
La formulation des questions, ou « prompts », influence la cohérence de la conversation. Pour obtenir les meilleurs résultats d'un modèle de langage, il est essentiel de maîtriser l'art du prompting, c'est-à-dire la formulation des requêtes ou instructions. La clarté est primordiale:
- Utilisez un langage simple et direct, en évitant les questions trop longues ou complexes. Décomposez les requêtes en plusieurs questions plus simples pour des réponses plus précises.
- Précisez si besoin des contraintes de formats spécifiques : Si vous avez besoin d’une réponse dans un certain format (liste, tableau, résumé, etc.), précisez-le dans le prompt. Vous pouvez également préciser les étapes à suivre et les critères de qualité souhaités.
- Spécifiez le rôle du modèle : Par exemple, commencez par “Agis comme un expert en…” ou “Imagine que tu es un enseignant…” pour orienter le ton et la perspective de la réponse.
- Contextualisez vos questions : si nécessaire, fournissez des exemples pertinents pour guider le modèle.
- Encouragez le raisonnement: utilisez l’incitation au raisonnement pas à pas (Chain-of-Thought Prompting) pour demander au modèle d'expliciter son raisonnement, ce qui rend les réponses plus robustes.
Les modèles conversationnels sont sensibles aux variations de formulation: un langage simple, des questions courtes et une reformulation si nécessaire peuvent aider à guider le modèle vers des réponses pertinentes. Testez et affinez vos prompts pour trouver la formulation la plus efficace !
L'IA conversationnelle répond directement en formulant des phrases à partir d’un grand ensemble de données sur lesquelles le modèle a été entraîné, tandis qu’un moteur de recherche propose des liens et des ressources pour que l’internaute les explore lui-même.
Nous choisissons les modèles en fonction de leur popularité, de leur diversité et de la pertinence pour les utilisateurs. Nous veillons particulièrement à rendre accessibles des modèles dits open weights (semi-ouverts) et de taille différentes.
L’inférence, c’est-à-dire le fait de pouvoir interroger les modèles, est prise en charge par le projet. Pour la plupart des modèles, nous passons par les API d’Open Router et de Hugging Face et nous réglons les coûts à l’usage, au jeton.
Les modèles quantisés sont optimisés pour consommer moins de ressources en simplifiant certains calculs tout en visant la meilleure qualité de réponse.
La quantisation est une technique d'optimisation qui consiste à réduire la précision des nombres utilisés pour représenter les paramètres d'un modèle d'IA. Cela permet de diminuer la taille du modèle et d'accélérer les calculs, ce qui est particulièrement avantageux pour l'inférence sur des machines limitées en ressources.
La capacité d'un modèle à parler plusieurs langues est liée à la diversité linguistique de ses données d'entraînement et non au pays. Les LLM utilisent d'énormes corpus dans de nombreuses langues, mais la répartition des langues dans les données d'entraînement n'est pas uniforme. Une surreprésentation de l'anglais peut entraîner des limitations dans d'autres langues. Ces limitations se traduisent par exemple par des anglicismes ou une incapacité à générer des contenus dans certaines langues classées « en danger » par l'UNESCO.
L'exactitude et la richesse du vocabulaire d'un modèle dépendent des données utilisées pour son apprentissage.
Rares sont les acteurs à être “transparents” sur les sources de données utilisées dans les corpus d’entraînement. Ces informations sont souvent confidentielles pour des raisons légales et commerciales.
Les données de préférence servent à améliorer les modèles lors d'entraînements futurs.
En comparant à l'aveugle les réponses de deux modèles, les utilisateurs de compar:IA expriment leurs préférences, indiquant ainsi quelles réponses sont les plus pertinentes. Ces données de préférence peuvent être utilisées pour affiner l'alignement des modèles, c'est-à-dire pour les entraîner à générer des réponses plus conformes aux attentes et aux préférences des utilisateurs.
Il s'agit d'un processus itératif, où le modèle apprend progressivement à générer de meilleures réponses en fonction des retours formulés par les humains sur la qualité des réponses. En étant exposés à des données de préférence, les modèles apprennent à les intégrer dans leur processus de génération de réponses.
La spécificité des données collectées sur la plateforme compar:IA est qu’elles sont en français et qu’elles correspondent à des tâches réelles des utilisateurs. Ces données reflètent des préférences humaines dans un contexte linguistique et culturel précis. Elles permettent dans un second temps d'ajuster les modèles pour qu’ils soient plus pertinents, précis et adaptés aux usages des utilisateurs, tout en comblant les éventuels biais ou lacunes des modèles actuels.
compar:IA se positionne comme un outil d'évaluation et d'alignement spécifique au français, axé sur la qualité des réponses et la collecte de données de préférence, se distinguant ainsi de l'approche de classement global de chatbot arena développé par lmsys.org et de l'alignement éthique des modèles d’IA de Prism Alignment Project.
compar:IA utilise la méthodologie développée par Ecologits (GenAI Impact) pour fournir un bilan énergétique qui permet aux utilisateurs de comparer l'impact environnemental de différents modèles d'IA pour une même requête. Cette transparence est essentielle pour encourager le développement et l'adoption de modèles d'IA plus éco-responsables.
Ecologits applique les principes de l'analyse du cycle de vie (ACV) conformément à la norme ISO 14044 en se concentrant pour le moment sur l'impact de l'inférence (c'est-à-dire l'utilisation des modèles pour répondre aux requêtes) et de la fabrication des cartes graphiques (extraction des ressources, fabrication et transport).
La consommation électrique du modèle est estimée en tenant compte de divers paramètres tels que la taille du modèle d'IA utilisé, la localisation des serveurs où sont déployés les modèles et le nombre de tokens de sortie. Le calcul de l’indicateur de potentiel de réchauffement climatique exprimé en équivalent CO2 est dérivé de la mesure de consommation électrique du modèle.
Il est important de noter que les méthodologies d'évaluation de l'impact environnemental de l'IA sont encore en développement.
La localisation des centres de données joue un rôle dans l'empreinte carbone de l'IA. Si un modèle est entraîné ou utilisé dans un pays fortement dépendant des énergies fossiles, son impact environnemental sera plus important que s'il est hébergé dans un pays utilisant majoritairement des énergies renouvelables.
La méthode d'analyse de l'impact environnemental de l'IA développée par Ecologits (de GenAI Impact), intègre des données sur le mix énergétique des différents pays où se situent les serveurs. Cela permet d'obtenir une estimation plus précise et nuancée de l'empreinte carbone réelle de l’inférence sur les différents modèles d’IA générative.
Les indicateurs d'impact écologique actuels se focalisent principalement sur l'impact de l'inférence, c'est-à-dire l'utilisation des modèles d'IA pour répondre aux requêtes. Cette approche peut donner l'illusion que l'inférence est moins énergivore que l'entraînement des modèles. Cependant, la réalité est plus complexe. Prenons l'analogie de la voiture :
- Construire une voiture (l'entraînement) est un processus ponctuel et gourmand en ressources.
- Chaque trajet en voiture (l'inférence) consomme moins d'énergie, mais ces trajets sont répétés quotidiennement, et leur nombre est potentiellement immense.
De la même manière, l'impact cumulé de l'inférence, à l'échelle de millions d'utilisateurs effectuant des requêtes quotidiennement, peut s'avérer supérieur à l'impact de l'entraînement initial. C'est pourquoi il est crucial que les outils d'évaluation de l'empreinte carbone de l'IA prennent en compte l'ensemble du cycle de vie des modèles, de l'entraînement à l'utilisation en production
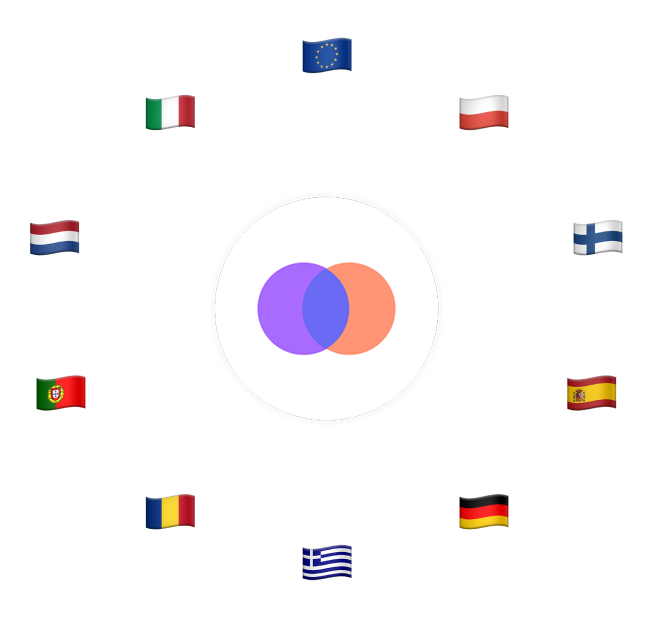
Oui, l'internationalisation de compar:IA est en cours. Nous commençons par un élargissement à trois pays pilotes : la Lituanie, la Suède et le Danemark. Cette première phase permet de tester l’approche et d'adapter l’interface à différents contextes linguistiques et culturels européens. À terme, le cercle pourra s'étendre à davantage de langues européennes selon les retours d'expérience de ces pays pilotes. L'objectif est de construire progressivement un véritable commun numérique européen pour l'évaluation humaine des IA conversationelles, avec une gouvernance collaborative qui reste encore à définir entre les différents pays participants.
Le développement d’un plateforme européenne de comparaison des modèles d’IA conversationnelle offre plusieurs avantages concrets. Elle permet de collecter des données de préférence reflétant les besoins réels des utilisateurs européens, améliorant ainsi la pertinence des modèles pour ce public. Elle garantit ainsi une meilleure représentation des langues et cultures européennes, souvent sous-représentées dans les évaluations globales dominées par l'anglais. Elle assure aussi une conformité avec les réglementations européennes (RGPD, AI Act) et intègre des critères d'évaluation alignés sur les priorités européennes comme la durabilité environnementale et la transparence algorithmique. Enfin, elle favorise l'émergence d'un écosystème d'IA européen compétitif et autonome.
Partenaires institutionnels
Partenaires de diffusion
Nous créons un réseau de partenaires intégrant le comparateur dans leur offre de services et de formation.
Vous souhaitez utiliser le comparateur pour répondre à un besoin métier ?
Dites nous en plusPartenaires académiques
Nous avons à coeur que les jeux de données générés alimentent des travaux de recherche multidisciplinaires mêlant sciences humaines et sociales et data science.
Vous menez un projet de recherche et avez des suggestions ou besoin de précision sur la démarche et/ou les jeux de données produits ?
Nous contacterServices mis à contribution


Les calculs d’impacts environnementaux reposent sur les produits ci dessus.