Ne vous fiez pas aux réponses d’une seule IA
Discutez avec deux IA à l’aveugle et évaluez leurs réponses
À quoi sert compar:IA ?
compar:IA est un outil gratuit qui permet de sensibiliser les citoyens à l’IA générative et à ses enjeux.
Comparer les réponses de différents modèles d’IA
Discutez et développez votre esprit critique en donnant votre préférence


Tester au même endroit les dernières IA de l’écosystème
Testez différents modèles, propriétaires ou non, de petites et grandes tailles...
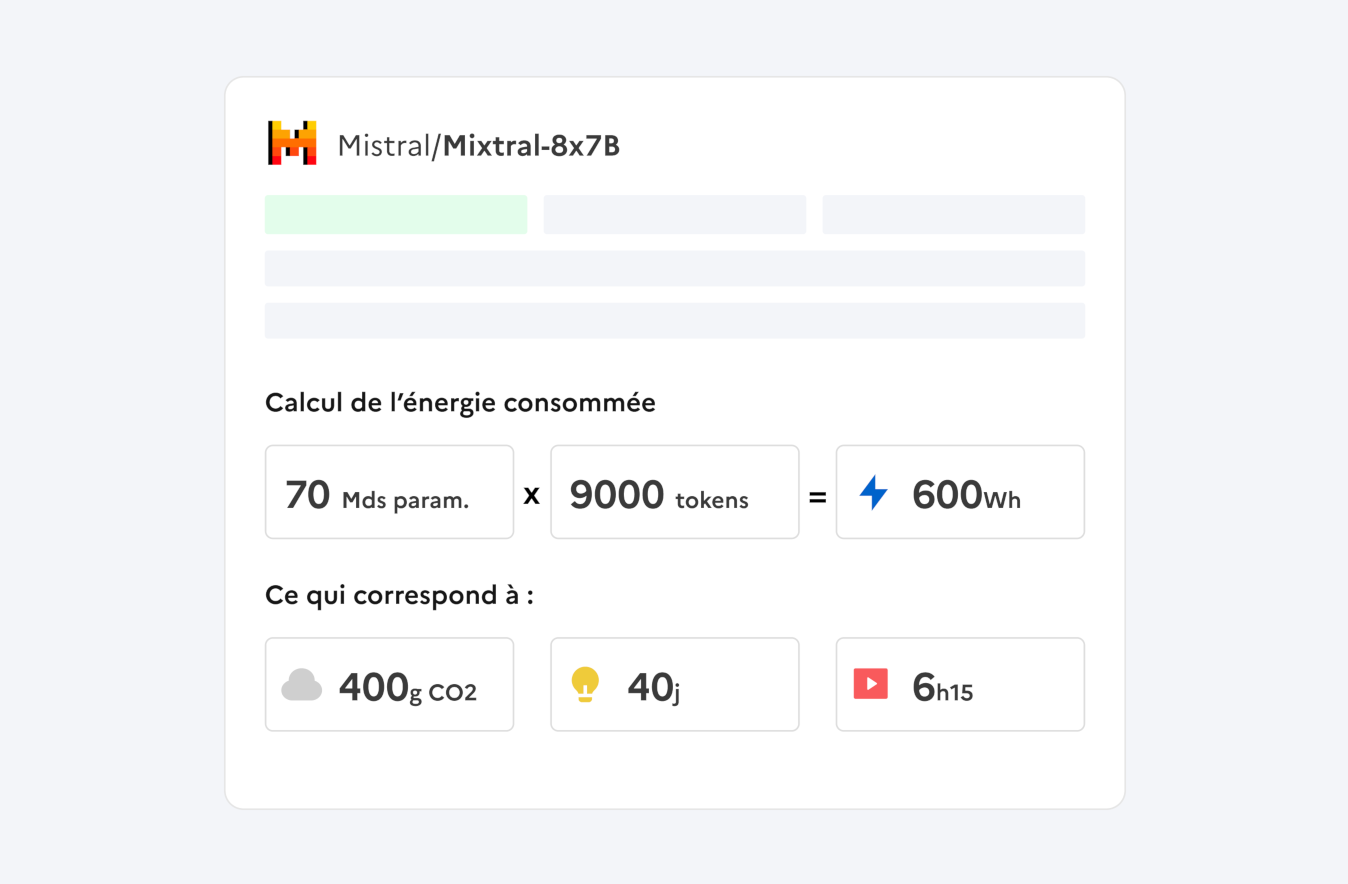
Mesurer l’empreinte écologique des questions posées aux IA
Découvrez l’impact environnemental de vos discussions avec chaque modèle

Pourquoi votre vote est important ?
L’outil s’adresse également aux experts IA et aux formateurs pour des usages plus spécifiques

Vos préférences
Après discussion avec les IA, vous indiquez votre préférence pour un modèle selon des critères donnés, tels que la pertinence ou l’utilité des réponses.

Les jeux de données par langue
Toutes les questions posées et les votes sont compilés dans des jeux de données et publiés librement après anonymisation.

Des modèles affinés sur la langue spécifique
À terme, les entreprises et les acteurs universitaires peuvent exploiter les jeux de données pour entrainer de nouveaux modèles plus respectueux de la diversité linguistique et culturelle.
Les usages spécifiques de compar:IA
L’outil s’adresse également aux experts IA et aux formateurs pour des usages plus spécifiques
Exploiter les données
Développeurs, chercheurs, éditeurs de modèles… accédez aux jeux de données compar:IA pour améliorer les modèles
Explorer les modèles
Consultez au même endroit toutes les caractéristiques et conditions d’utilisation des modèles
Former et sensibiliser
Utilisez le comparateur comme un support pédagogique de sensibilisation à l’IA auprès de votre public
Qui sommes-nous ?
Le comparateur est porté au sein du Ministère de la Culture par une équipe pluridisciplinaire réunissant expert en Intelligence artificielle, développeurs, chargé de déploiement, designer, avec pour mission de rendre les IA conversationnelles plus transparentes et accessibles à toutes et tous.


Qui est à l’origine du projet ?
Le comparateur a été conçu et développé dans le cadre d’une start-up d’Etat portée par le ministère de la Culture et intégrée au programme Beta.gouv.fr de la Direction interministérielle du numérique (DINUM) qui aide les administrations publiques françaises à construire des services numériques utiles, simples et faciles à utiliser.


Vos questions les plus courantes
Vous avez posé la question suivante “explique-moi la motion de censure à l'œuvre actuellement en France à l'Assemblée nationale et cite-moi tes sources” et avez été déçu·e des réponses ? C’est normal…
Les modèles d'IA conversationnels “bruts” ne peuvent pas répondre aux questions sur l'actualité la plus récente. Ils sont entraînés sur des ensembles de données statiques et ne peuvent pas interagir avec le web ou ouvrir des liens. Ils n'ont pas la capacité de se mettre à jour en temps réel avec les événements qui se déroulent dans le monde. Les informations auxquelles le modèle a accès sont limitées à la date de son dernier entraînement.
Par conséquent, si vous posez une question sur un fait d’actualité récent, le modèle s'appuiera sur des informations potentiellement obsolètes, risquant de générer des réponses inexactes.
Dans le cas de Perplexity, Copilot ou ChatGPT, les modèles d’IA conversationnelle dits “bruts” sont associés à d’autres briques technologiques qui permettent de se connecter à internet pour accéder à des informations en temps réel. On parle alors “d’agents conversationnels”.
Nous choisissons les modèles en fonction de leur popularité, de leur diversité et de la pertinence pour les utilisateurs. Nous veillons particulièrement à rendre accessibles des modèles dits open weights (semi-ouverts) et de taille différentes.
La spécificité des données collectées sur la plateforme compar:IA est qu’elles sont en français et qu’elles correspondent à des tâches réelles des utilisateurs. Ces données reflètent des préférences humaines dans un contexte linguistique et culturel précis. Elles permettent dans un second temps d'ajuster les modèles pour qu’ils soient plus pertinents, précis et adaptés aux usages des utilisateurs, tout en comblant les éventuels biais ou lacunes des modèles actuels.
compar:IA utilise la méthodologie développée par Ecologits (GenAI Impact) pour fournir un bilan énergétique qui permet aux utilisateurs de comparer l'impact environnemental de différents modèles d'IA pour une même requête. Cette transparence est essentielle pour encourager le développement et l'adoption de modèles d'IA plus éco-responsables.
Ecologits applique les principes de l'analyse du cycle de vie (ACV) conformément à la norme ISO 14044 en se concentrant pour le moment sur l'impact de l'inférence (c'est-à-dire l'utilisation des modèles pour répondre aux requêtes) et de la fabrication des cartes graphiques (extraction des ressources, fabrication et transport).
La consommation électrique du modèle est estimée en tenant compte de divers paramètres tels que la taille du modèle d'IA utilisé, la localisation des serveurs où sont déployés les modèles et le nombre de tokens de sortie. Le calcul de l’indicateur de potentiel de réchauffement climatique exprimé en équivalent CO2 est dérivé de la mesure de consommation électrique du modèle.
Il est important de noter que les méthodologies d'évaluation de l'impact environnemental de l'IA sont encore en développement.
Oui, l'internationalisation de compar:IA est en cours. Nous commençons par un élargissement à trois pays pilotes : la Lituanie, la Suède et le Danemark. Cette première phase permet de tester l’approche et d'adapter l’interface à différents contextes linguistiques et culturels européens. À terme, le cercle pourra s'étendre à davantage de langues européennes selon les retours d'expérience de ces pays pilotes. L'objectif est de construire progressivement un véritable commun numérique européen pour l'évaluation humaine des IA conversationelles, avec une gouvernance collaborative qui reste encore à définir entre les différents pays participants.
Abonnez-vous à notre lettre d'information
Retrouvez les dernières actualités du projet : partenariats, intégration de nouveaux modèles, publications de jeux de données et nouvelles fonctionnalités !